可变对象与不可变对象 在面向对象中,对象是类的一个实例;而在Python中,对象就是变量。
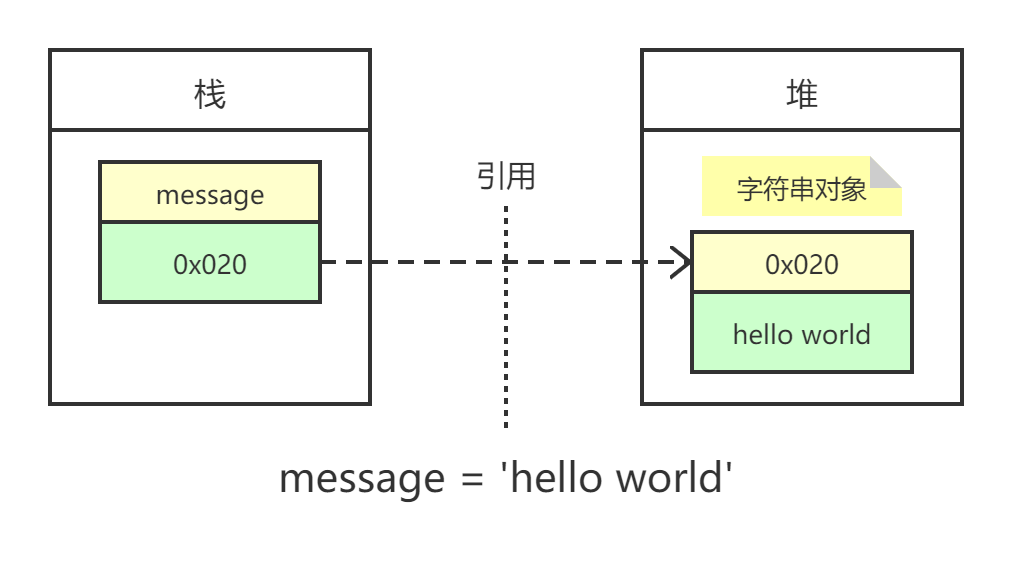
存储方式 在理解可变与不可变之前,先来看看Python对象在内存中是如何存储的:id(标识。在CPython中,对应内存地址)、type(类型)、value(值)。
1 2 3 4 5 >>> message = 'hello' >>> id(message)2836204005360 >>> type(message)<class 'str '>
其中,id([object]) 获取对象的内存地址,type([object]) 获取对象的类型。message 并不是真正的对象,它是对象的引用,相当于记录了对象在堆空间的地址,通过这个地址可以访问到对应的对象。
不可变(immutable)与可变(mutable) 上例中,存储在堆中的字符串对象是独立的(没有引用外部),所以它本身是不可变的。当改变某个变量时,由于其所引用的对象不可变,所以创建了新对象,变量再指向这个新对象的地址。
1 2 3 >>> message += ' world' >>> id(message)2836203997232
内置的不可变对象有 int、float、str、tuple。
同理,可变对象:对象在内存中的值可以被改变。
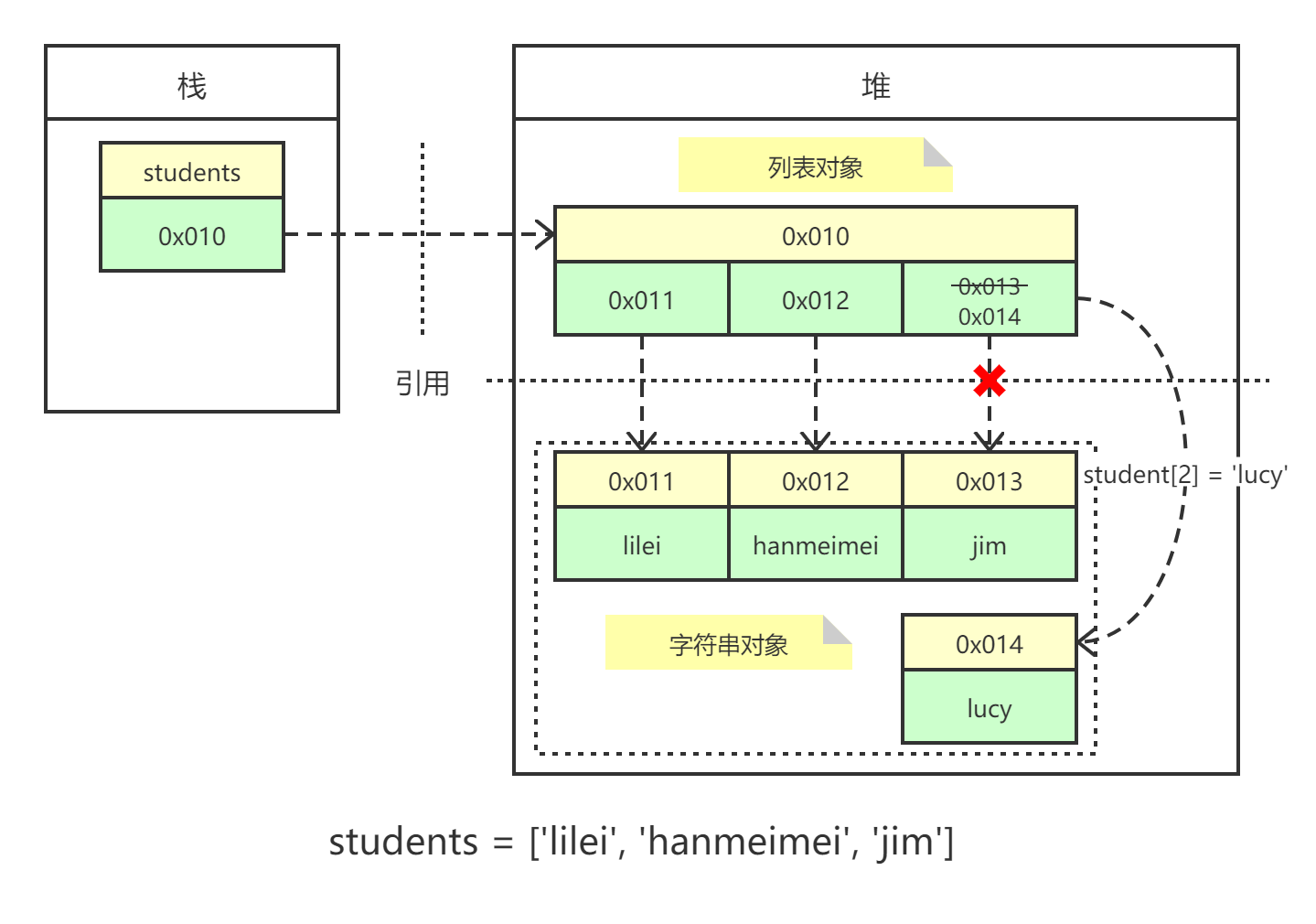
1 2 3 4 5 6 >>> students = ['lilei' , 'hanmeimei' , 'jim' ]>>> id(students)2836201579200 >>> students[2 ] = 'lucy' >>> id(students)2836201579200
students 引用的还是原来那个列表对象,但对象的值发生了改变,即,students[3] 指向了不同的字符串对象。
可哈希对象 官方文档上对 hashable 做了明确说明:
一个对象的哈希值如果在其生命周期内固定不变(这需要 __hash__() 方法)且可以与其他对象进行比较(这需要 __eq__() 方法),那么这个对象就是可哈希对象(hashable)。相等的可哈希对象必须具有相同的哈希值。id()。https://docs.python.org/zh-cn/3.9/glossary.html#term-hashable
但若重写 __hash__() 方法、__eq__() 方法,则可能改变自定义对象的可哈希性:
如果一个类没有定义 __eq__() 方法,那么也不应该定义 __hash__() 操作;如果它定义了 __eq__() 但没有定义 __hash__(),则其实例将不可被用作可哈希集的项(即 unhashable)。如果一个类定义了可变对象并实现了 __eq__() 方法,则不应该实现 __hash__(),因为可哈希集的实现要求键的哈希集是不可变的(如果对象的哈希值发生改变,它将处于错误的哈希桶中)。https://docs.python.org/zh-cn/3/reference/datamodel.html#object.__hash __
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import randomclass MyObject (object) : def __init__ (self, hash_=None) : self.hash_ = 222 if hash_ is None else hash_ def __hash__ (self) : """ 若在对象生命周期内哈希值发生改变,则会导致哈希集发生混乱。 比如当此对象作为字典的键时,每次通过此对象从字典中取值都不一定能返回正确的数据。 """ return self.hash_ def __eq__ (self, other) : return False my_dict = {} o1 = MyObject() print('o1\t__hash__: %s, hash: %s, id: %s' % (o1.__hash__, hash(o1), id(o1))) my_dict[o1] = 'world1' o2 = MyObject() print('o2\t__hash__: %s, hash: %s, id: %s' % (o2.__hash__, hash(o2), id(o2))) my_dict[o2] = 'world2' print(my_dict) print('my_dict[o1]: %s, my_dict[o2]: %s' % (my_dict.get(o1), my_dict.get(o2))) """ 执行结果: o1 __hash__: <bound method MyObject.__hash__ of <__main__.MyObject object at 0x000001CDC3B2AFD0>>, hash: 222, id: 1983263190992 o2 __hash__: <bound method MyObject.__hash__ of <__main__.MyObject object at 0x000001CDC3B2AF70>>, hash: 222, id: 1983263190896 {<__main__.MyObject object at 0x000001CDC3B2AFD0>: 'world1', <__main__.MyObject object at 0x000001CDC3B2AF70>: 'world2'} my_dict[o1]: world1, my_dict[o2]: world2 若 __eq__() 返回 True,则 o1 等于 o2,执行结果为: o1 __hash__: <bound method MyObject.__hash__ of <__main__.MyObject object at 0x00000132260AAFD0>>, hash: 222, id: 1314898227152 o2 __hash__: <bound method MyObject.__hash__ of <__main__.MyObject object at 0x00000132260AAF70>>, hash: 222, id: 1314898227056 {<__main__.MyObject object at 0x00000132260AAFD0>: 'world2'} my_dict[o1]: world2, my_dict[o2]: world2 """
所以,理论上,可哈希对象一定是不可变对象,但 unhashable 未必是可变对象,也有可能仅仅是因为没有实现 __hash__()。
浅拷贝(shallow copy)与深拷贝(deep copy) 赋值 在讲拷贝之前,先来看看常见的赋值操作。
1 2 3 4 >>> str1 = 'hello world' >>> str2 = str1>>> id(str1), id(str2)(2195276276528 , 2195276276528 )
str1 和 str2 指向同一个字符串对象。
浅拷贝 拷贝分浅拷贝和深拷贝,copy 模块分别提供了两个API:copy.copy(x) 和 copy.deepcopy(x)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import copylist_a = ['2020' ] list_b = copy.copy(list_a) list_a[0 ] = '2021' print('list_a: %s, list_b: %s' % (list_a, list_b)) list_a = ['2020' , ['aaa' ]] list_b = copy.copy(list_a) list_a[1 ][0 ] = 'bbb' print('id(list_a[1]): %s, id(list_b[1]): %s' % (id(list_a[1 ]), id(list_b[1 ]))) print('list_a: %s, list_b: %s' % (list_a, list_b))
示例1:list_a[0] 指向的子对象是一个不可变对象,拷贝后 list_b[0] 也指向同一个字符串对象,所以修改 list_a[0] 指向另一个字符串对象并不影响 list_b[0]。list_a[1] 指向的子对象是一个可变对象,浅拷贝只是拷贝 list_a[1] 的值(并不会拷贝变量指向的对象),即 list_b[1] 和 list_a[1] 指向同一个列表对象,所以修改 list_a[1][0] 也会影响到 list_b[1][0]。
深拷贝 相对于浅拷贝,深拷贝就很彻底了,会递归拷贝每一层对象。
1 2 3 4 5 list_a = ['2020' , ['aaa' ]] list_b = copy.deepcopy(list_a) list_a[1 ][0 ] = 'bbb' print('id(list_a[1]): %s, id(list_b[1]): %s' % (id(list_a[1 ]), id(list_b[1 ]))) print('list_a: %s, list_b: %s' % (list_a, list_b))
list_a[1] 和 list_b[1] 指向了不同的列表对象。
最后,再次说明下,拷贝只是复制内存地址,并不会复制非容器类型(int、float、str),所以如下代码实际上是一样的操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import copystr1 = 'hello world' str2 = str1 str3 = copy.copy(str1) str4 = copy.deepcopy(str1) print('id(str1): %s' % id(str1)) print('id(str2): %s' % id(str2)) print('id(str3): %s' % id(str3)) print('id(str4): %s' % id(str4)) """ 执行结果: id(str1): 2292725768816 id(str2): 2292725768816 id(str3): 2292725768816 id(str4): 2292725768816 """
对 str1 的浅拷贝 和 深拷贝,实际上都只是赋值而已。
自定义对象的拷贝 虽然Python默认提供了自定义对象的拷贝实现,但想要明白具体拷贝了什么并能按需实现自己的拷贝逻辑,还是得先弄懂拷贝的原理。
拷贝的原理 直接看源码:https://github.com/python/cpython/blob/3.9/Lib/copy.py https://docs.python.org/zh-cn/3/library/copy.html
浅拷贝和深拷贝之间的区别仅在于复合对象(包含其他对象的对象,eg. 列表、类实例):
浅拷贝将构造一个新的复合对象,然后将所包含的对象直接插入到新的复合对象中。
深拷贝将构造一个新的复合对象,然后递归地拷贝所包含的对象并插入到新的复合对象中。
不同于浅拷贝,深拷贝存在两个问题:
递归对象(直接或间接地包含对自己的引用)可能会导致循环拷贝。
拷贝所有导致拷贝太多,如共享的数据结构等。
针对这两个问题,有对应的解决方案:
保存一张已拷贝的对象表。1 2 3 4 5 6 7 8 9 10 11 12 def deepcopy (x, memo=None, _nil=[]) : """Deep copy operation on arbitrary Python objects. See the module's __doc__ string for more info. """ if memo is None : memo = {} d = id(x) y = memo.get(d, _nil) if y is not _nil: return y
允许在自定义类中重写拷贝实现。
内置对象中,浅拷贝的实现相对简单,可以自己看源码理解;深拷贝主要用递归拷贝来实现,如:
1 2 3 4 5 6 7 def _deepcopy_dict (x, memo, deepcopy=deepcopy) : y = {} memo[id(x)] = y for key, value in x.items(): y[deepcopy(key, memo)] = deepcopy(value, memo) return y d[dict] = _deepcopy_dict
接下来,着重来说说自定义对象的拷贝实现:__copy__/__deepcopy__->dispatch_table->__reduce_ex__/__reduce__->__getstate__/__setstate__
__copy__ 和 __deepcopy__首先判断对象中是否有 __copy__ 或 __deepcopy__。__copy__ 和 __deepcopy__ 分别对应浅拷贝和深拷贝的自定义实现。__copy__ 和 __deepcopy__ ?按照前面梳理的拷贝思路来:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 import copyclass MyObject (object) : def __init__ (self) : print('__init__' ) self.name = 'lilei' self.message = ['hi' , 'hanmeimei' ] def __copy__ (self) : print('__copy__' ) cls = self.__class__ obj = cls.__new__(cls) obj.__dict__.update(self.__dict__) return obj def __deepcopy__ (self, memo) : print('__deepcopy__' ) cls = self.__class__ obj = cls.__new__(cls) memo[id(self)] = obj for k, v in self.__dict__.items(): setattr(obj, k, copy.deepcopy(v, memo)) return obj print('----- 自定义对象浅拷贝 -----' ) o1 = MyObject() o2 = copy.copy(o1) o2.message[1 ] = 'lucy' print(o1.message, o2.message) print('----- 自定义对象深拷贝 -----' ) o1 = MyObject() o2 = copy.deepcopy(o1) o2.message[1 ] = 'lucy' print(o1.message, o2.message) """ 执行结果: ----- 自定义对象浅拷贝 ----- __init__ __copy__ ['hi', 'lucy'] ['hi', 'lucy'] ----- 自定义对象深拷贝 ----- __init__ __deepcopy__ ['hi', 'hanmeimei'] ['hi', 'lucy'] """
其中,__dict__ 存储了对象的一些属性(不包含特殊属性等);类和对象分别拥有自己的 __dict__。
dispatch_table 如果没有自定义的 __copy__ 或 __deepcopy__,会接着判断 dispatch_table 中是否有对应类型的 归约函数 。copyreg 模块中用来保存 规约函数 的字典,以对象类型作为key;通过 copyreg.pickle 进行添加。https://docs.python.org/zh-cn/3/library/copyreg.html#copyreg.pickle https://github.com/python/cpython/blob/3.9/Lib/copyreg.py#L12
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 import copy, copyregclass MyObject (object) : def __init__ (self, message=None) : print('__init__' ) self.name = 'lilei' self.message = ['hi' , 'hanmeimei' ] if message is None else message def pickle_my_object (obj) : print('pickling a MyObject instance...' ) return MyObject, (obj.message,), obj.__dict__ copyreg.pickle(MyObject, pickle_my_object) print('----- 自定义对象浅拷贝 -----' ) o1 = MyObject() o2 = copy.copy(o1) o2.message[1 ] = 'lucy' print(o1.message, o2.message) print('----- 自定义对象深拷贝 -----' ) o1 = MyObject() o2 = copy.deepcopy(o1) o2.message[1 ] = 'lucy' print(o1.message, o2.message) print('----- 序列化测试 -----' ) o1 = MyObject() print('--- pickle ---' ) data = pickle.dumps(o1) print('--- unpickle ---' ) o2 = pickle.loads(data) o2.message[1 ] = 'lucy' print(o1.message, o2.message) """ 执行结果: ----- 自定义对象浅拷贝 ----- __init__ pickling a MyObject instance... __init__ ['hi', 'lucy'] ['hi', 'lucy'] ----- 自定义对象深拷贝 ----- __init__ pickling a MyObject instance... __init__ ['hi', 'hanmeimei'] ['hi', 'lucy'] ----- 序列化测试 ----- __init__ --- pickle --- pickling a MyObject instance... --- unpickle --- __init__ ['hi', 'hanmeimei'] ['hi', 'lucy'] """
对比之下可以看出,拷贝实际上就是通过序列化和反序列化来实现的 。__init__。https://github.com/python/cpython/blob/3.9/Lib/copy.py#L264
__reduce_ex__ 或 __reduce__
dispatch_table 可能不够灵活,特别是想要基于对象类型以外的其他规则来对序列化进行定制,或是想要对函数和类的序列化进行定制的时候。reducer_override() 方法(Python3.8支持)。__reduce__(),它也可以选择返回 NotImplemented 来回退到传统行为。https://docs.python.org/zh-cn/3/library/pickle.html#custom-reduction-for-types-functions-and-other-objects reducer_override -> dispatch_table -> __reduce_ex__ -> __reduce__https://github.com/python/cpython/blob/3.9/Lib/pickle.py#L535
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 import copy, io, pickleclass MyObject (object) : def __init__ (self, message=None) : print('__init__' ) self.name = 'lilei' self.message = ['hi' , 'hanmeimei' ] if message is None else message class MyPickler (pickle.Pickler) : def reducer_override (self, obj) : """为 MyObject 类创建的对象定义 reducer""" if getattr(obj, '__class__' , None ) is MyObject: print('--- reducer_override ---' ) return MyObject, (obj.message,), obj.__dict__ else : return NotImplemented print('----- 自定义对象浅拷贝 -----' ) o1 = MyObject() o2 = copy.copy(o1) o2.message[1 ] = 'lucy' print(o1.message, o2.message) print('----- 自定义对象深拷贝 -----' ) o1 = MyObject() o2 = copy.deepcopy(o1) o2.message[1 ] = 'lucy' print(o1.message, o2.message) print('----- 序列化测试 -----' ) o1 = MyObject() f = io.BytesIO() p = MyPickler(f) p.dump(o1) o2 = pickle.loads(f.getvalue()) o2.message[1 ] = 'lucy' print(o1.message, o2.message) """ 执行结果: ----- 自定义对象浅拷贝 ----- __init__ ['hi', 'lucy'] ['hi', 'lucy'] ----- 自定义对象深拷贝 ----- __init__ ['hi', 'hanmeimei'] ['hi', 'lucy'] ----- 序列化测试 ----- __init__ reducer_override __init__ ['hi', 'hanmeimei'] ['hi', 'lucy'] """
相比 __reduce__,__reduce_ex__ 支持指定序列化协议版本,主要用于为以前的Python版本提供向后兼容。__reduce__ 的定义详见官方文档:https://docs.python.org/zh-cn/3/library/pickle.html#object.__reduce __
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import copyclass MyObject (object) : def __init__ (self, message=None) : print('__init__' ) self.name = 'lilei' self.message = ['hi' , 'hanmeimei' ] if message is None else message def __reduce__ (self) : print('__reduce__' ) return self.__class__, (self.message,), self.__dict__ print('----- 自定义对象浅拷贝 -----' ) o1 = MyObject() o2 = copy.copy(o1) o2.message[1 ] = 'lucy' print(o1.message, o2.message) print('----- 自定义对象深拷贝 -----' ) o1 = MyObject() o2 = copy.deepcopy(o1) o2.message[1 ] = 'lucy' print(o1.message, o2.message) """ 执行结果: ----- 自定义对象浅拷贝 ----- __init__ __reduce__ __init__ ['hi', 'lucy'] ['hi', 'lucy'] ----- 自定义对象深拷贝 ----- __init__ __reduce__ __init__ ['hi', 'hanmeimei'] ['hi', 'lucy'] """
可以看出,reducer_override() 和 __reduce__ 的返回数据跟 dispatch_table 的处理方式是一样,都初始化创建了新的对象。
__getstate__ 和 __setstate__实际上,前面介绍的都不是Python默认的拷贝实现,而是通过几个特殊方法来实现 __reduce__。https://docs.python.org/zh-cn/3/library/pickle.html#object.__getstate __
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 import copy, pickleclass MyObject (object) : def __init__ (self, message=None) : print('__init__' ) self.name = 'lilei' self.message = ['hi' , 'hanmeimei' ] if message is None else message def __getstate__ (self) : print('__getstate__' ) state = self.__dict__ return state def __setstate__ (self, state) : print('__setstate__' ) self.__dict__.update(state) print('----- 自定义对象浅拷贝 -----' ) o1 = MyObject() o2 = copy.copy(o1) o2.message[1 ] = 'lucy' print(o1.message, o2.message) print('----- 自定义对象深拷贝 -----' ) o1 = MyObject() o2 = copy.deepcopy(o1) o2.message[1 ] = 'lucy' print(o1.message, o2.message) print('----- 序列化测试 -----' ) o1 = MyObject() print('--- pickle --- ' ) data = pickle.dumps(o1) print('--- unpickle ---' ) o2 = pickle.loads(data) o2.message[1 ] = 'lucy' print(o1.message, o2.message) """ 执行结果: ----- 自定义对象浅拷贝 ----- __init__ __getstate__ __setstate__ ['hi', 'lucy'] ['hi', 'lucy'] ----- 自定义对象深拷贝 ----- __init__ __getstate__ __setstate__ ['hi', 'hanmeimei'] ['hi', 'lucy'] ----- 序列化测试 ----- __init__ --- pickle --- __getstate__ --- unpickle --- __setstate__ ['hi', 'hanmeimei'] ['hi', 'lucy'] """
可以看出,实际上,__getstate__ 对应序列化操作,__setstate__ 对应反序列化操作。
当实例解封时,它的 __init__() 方法通常不会被调用。其默认动作是:obj = cls.__new__(cls)),然后还原其属性(obj.__dict__.update(attributes))。https://docs.python.org/zh-cn/3/library/pickle.html#pickle-inst
几个问题 关于堆栈 堆和栈是两个不同的概念。
自定义对象和函数是否为可变对象? 直观上理解,我们会觉得自定义对象肯定是可变对象,因为可以随意增删改属性而不影响变量指向的对象。https://www.zhihu.com/question/359026281 可变与不可变一般针对内置类型来说,区分可变与不可变是为了在特定场合下使用而给出的概念;脱离实际使用场景,纠结可变与不可变反而显得无意义。 dict 的 key 必须是不可变对象,这是因为 dict 根据 key 来计算 value 的存储位置(采用的是哈希算法),所以,要保证 Hash 的正确性,作为 key 的对象必须不可变。按照可变与不可变的定义,考虑的是对象的值而非属性 。
自定义对象默认是可哈希对象,同时也是不可变对象;只有重写 __eq__() 且未重写 __hash__() 时才是可变对象。__hash__() 实现,因而函数对象不可变。
参考资料 Python函数是可变对象还是不可变对象,https://www.zhihu.com/question/359026281 那些年我们踩过的那些坑 - 嵌套列表 How to override the copy/deepcopy operations for a Python object 浅拷贝、深拷贝完全解读