什么是分布式锁
锁的作用是解决在并发情况下共享资源的互斥问题。
(1)单机场景下(多线程):部分语言已原生实现了多线程加锁控制,eg. Java 的 Synchronized。
(2)分布式场景下:基于CAP定理,满足AP,通过 最终一致性 来保障C,所以,一般采用 分布式事务、分布式锁 等来保障数据的最终一致性。
锁的分类
- 线程是否需要对资源加锁
- 乐观锁:乐观地认为数据不会被修改,持有数据不会上锁,写入时使用 CAS 判断,适用于读多写少的场景。
- 悲观锁:悲观地认为数据会被修改,持有数据就会上锁。
- 多线程并发访问资源加锁实现细节,eg. Java 的 Synchronized
- 无锁:不加锁,用 CAS 控制资源读写。
- 偏向锁:适用于同一线程多次访问的情况,通过 ThreadID 直接返回已获取的锁。
- 轻量级锁:在偏向锁阶段,若多个线程同时访问,会撤销偏向锁,升级为轻量级锁,未获取到资源的线程会使用自旋获取锁。
- 重量级锁:自旋到达一定次数还未获取锁,膨胀为重量级锁,管理多个线程。
- 资源已被锁定,线程是否阻塞
- 自旋锁:不阻塞,循环判断(此循环并不一定是程序中的循环语法,主要指持续占用CPU时间片)是否获取锁。
适应性自旋锁:自旋的时间/次数不再固定,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。
eg. 如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也是很有可能再次成功,进而它将允许自旋等待持续相对更长的时间;
如果对于某个锁,自旋很少成功获得过,那在以后尝试获取这个锁时将可能省略掉自旋过程,直接阻塞线程,避免浪费处理器资源。 - 互斥锁:阻塞,等待重新调度获取锁。
- 自旋锁:不阻塞,循环判断(此循环并不一定是程序中的循环语法,主要指持续占用CPU时间片)是否获取锁。
- 多个线程是否能够共享一把锁:共享锁(eg. 信号量)、独占锁(又称 排他锁)。
- 是否重复获取:
- 不可重入锁:若当前线程执行某个方法已经获取了锁,那么此线程中不允许再次获取同一个锁。
- 可重入锁:线程可以重复获取同一个锁,eg. Java 的 ReentrantLock。
乐观锁和悲观锁
乐观锁
读取时不上锁,写入时会判断数据是否被修改过。
常见有两种实现方案:版本号机制 和 CAS(Compare And Swap)。
版本号机制
比如在数据表中加一个 version 字段来实现:
1 | select money,version from wallet where owner = 'xiaoming' |
CAS
CAS机制当中使用了3个基本操作数:内存地址V、旧的预期值A、要修改的新值B。
只有 A 和 内存地址V 当中的实际值相同时,才会将 内存地址V 对应的值修改为 B。
(1)CAS是硬件级别的原子操作
CAS指令 在 Intel CPU 上称为 CMPXCHG 指令,它的作用是将指定内存地址的内容与所给的某个值相比,如果相等,则将其内容替换为指令中提供的新值,如果不相等,则更新失败。
这一比较并交换的操作是原子的,不可以被中断。
(2)ABA问题
即,值从 A -> B -> A。感觉好像也没啥毛病?!举个栗子:
小明在某网站上有200积分,由于网站BUG,减100的积分兑换被Double触发,开启了2个处理线程:都是获取当前值200,要执行减100的操作。
理想情况下,只有一个成功,但如果线程A成功后,线程B因某种原因还在阻塞;
若这时候,刚好有100积分入账(即现在又有200积分),则当B恢复运行,预期值和当前值对比相同,导致误操作。
如何解决?给变量加个版本号,即,不仅要比较 期望值A 和 地址V中的实际值,还要比较变量的版本号是否一致。
- 假设地址V中存储着变量值A,当前版本号是01。
- 线程1获得了当前值A和版本号01,想要更新为B时被阻塞了。
- 期间,内存地址V中的变量发生了多次改变,版本号提升为03,但变量值仍然是A。
- 线程1恢复运行,经比较,获得的值和地址V的实际值均为A,但版本号不相等,所以本次更新失败。
Java中,AtomicStampedReference类就实现了用版本号做比较的CAS机制。
悲观锁
eg. MySQL 中的 读锁(共享锁) / 写锁(排他锁)。
通过事务进行读写加锁控制,eg.
1 | set autocommit = 0 // 关闭自动提交 |
其他事务在这个事务提交之前都无法对这条数据进行操作,起到了独占的作用。
具体应用
MySQL中的悲观锁
共享锁
Shared Locks,S锁,又称 读锁,加S锁的所有线程只能对资源进行读操作。
在事务中用 select ... lock in share mode:
1 | select username from user where uid=#{uid} lock in share mode; |
排他锁
Exclusive Locks,X锁,又称 写锁。
在事务中用 select ... for update:
1 | select username from user where uid=#{uid} for update; |
间隙锁
Gap Locks,不仅仅锁住所需要的行还会锁住一个范围的行,这个范围依据锁住的这行而定。
间隙锁只会出现在辅助索引上,唯一索引和主键索引是没有间隙锁;间隙锁(无论是共享锁还是排他锁)只会阻塞 INSERT 操作。
注:MySQL中 SELECT 默认不加锁、INSERT / DELETE / UPDATE 加排他锁(行锁 [ 实际上是锁索引不是锁记录 ],不加索引条件则为表锁)。
Redis
乐观锁:事务性流水线(watch / multi / exec)
带 WATCH命令 的事务会将客户端和被监视的键在数据库 watched_keys 字典中进行关联,当键被修改,程序会将所有监视键的客户端 REDIS_DIRTY_CAS 标识打开。
在客户端提交 EXEC命令 时,会检查 REDIS_DIRTY_CAS 标识,标识打开事务将不会被执行。
注:每个Redis数据库都保存着一个 watched_keys 字典来保存被监控的健,字典值是一个链表,链表中记录了所有监视相应键的客户端。
悲观锁:setnx / expire / del
setnx(SET if Not eXists)只会在健不存在的情况下为健设置值。
在取得锁之后,调用 expire命令 来为锁设置过期时间,使得Redis可以自动删除超时的锁。
(1)为了确保锁在客户端已经崩溃(在执行介于 setnx 和 expire 之间的时候崩溃是最糟糕的)的情况下仍然能够自动被释放,客户端会在尝试获取锁失败之后,检查锁的超时时间,并为未设置超时时间的锁设置超时时间。因此锁总会带有超时时间,并最终因为超时而自动被释放,使得其他客户端可以继续尝试获取已被释放的锁。
注:因为多个客户端在同一时间内设置的超时时间基本上都是相同的,所以即使有多个客户端同时为同一个锁设置超时时间,锁的超时时间也不会产生太大变化。
(2)Redis2.6.12 之后 set命令 支持 setnx+expire 的原子操作,即:SET key-with-expire-and-NX "hello" EX 10086 NX。
(3)另,如何避免误删呢?比如A线程执行太久,导致锁超时释放,B线程获取锁,这时候可能A线程刚好执行完调用DEL,就会把B刚获取的锁释放掉。
DEL时验证当前锁是否自己加的锁:在加锁的时候把当前的线程ID当做value(分布式的情况下,可以用UUID / 分布式ID),并在删除之前验证key对应的value是不是自己线程的ID。
注:_判断和释放是两个独立操作,为了原子性,可以用Lua脚本来实现_。
(4)上面说到,A线程执行太久,导致锁超时释放,B线程获取锁,如何避免呢?
可以给获取锁的当前线程开一个守护线程,用守护线程给快过期的锁“续航”。
eg. 比如锁超时时间为30s,那么守护线程可以在29s将expire延长10s,当A执行完成时显式关闭守护线程。
分布式锁的几种实现
Redis - Redlock
Redis的部署方式:单机、Master-Slave + Sentinel选举、Cluster。
注:Sentinel保障主备高可用;Cluster保障多主备(高可用的同时分机存储)。
Master-Slave下,Master故障时主从切换,可能会出现锁丢失。
所以,Cluster集群,Redlock原理大致如下:
假设有5个(大于3的奇数个)Master节点,通过以下步骤获取一把锁:
- 获取当前时间戳,单位是毫秒。
- 轮流尝试在每个Master节点上创建锁,过期时间设置较短,一般就几十毫秒。
- 尝试在大多数(超过半数)节点上建立一个锁,eg. 5个节点就要求是3个节点(n / 2 + 1)。
- 客户端计算建立好锁的时间(锁的真正有效时间等于设置的有效时间减去获取锁所使用的时间),如果建立锁的时间小于超时时间,就算建立成功。
- 若建锁失败,就依次删除节点上的锁。
- 其他需要考虑的:出错重试、时钟漂移等细节问题。
Redclock还是颇具争议的,可能还会存在不少的问题,无法保证加锁的过程一定正确:
http://zhangtielei.com/posts/blog-redlock-reasoning.html
http://zhangtielei.com/posts/blog-redlock-reasoning-part2.html
推荐使用现成的 Redis Client,eg. Redission(Java)。
Zookeeper - 临时有序节点
Znode 的一些特性:
- 有序节点 - 按创建的时间顺序对节点名称进行编号。
- 临时节点 / 持久节点 - 临时节点,即,会话结束或超时,自动删除;相对应的是 持久节点,节点一直存在除非明确删除。
- 事件监听 - 创建 / 删除 / 数据修改 / 变更 等,都会触发监听事件。
临时有序节点即按顺序创建的临时节点,当创建节点的客户端与zk断开连接后,临时节点会被删除,并触发监听事件。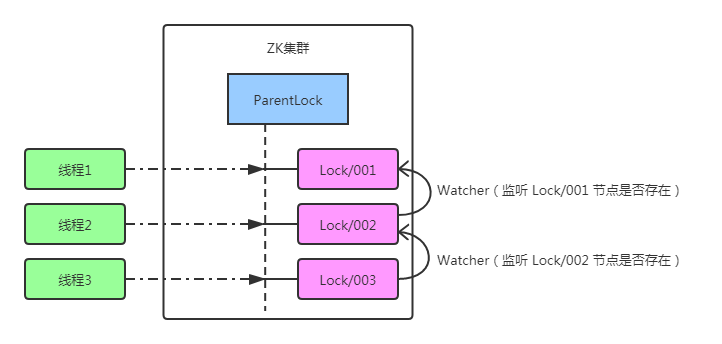
- 首先,创建一个持久节点 ParentLock,线程1想要获得锁,需在 ParentLock 下创建一个临时有序节点 Lock/001。
之后,线程1查找 ParentLock 下所有临时有序节点并排序,判断 Lock/001 是否为顺序最靠前,若是第一个节点,则获得锁。 - 线程2请求获得锁,在 ParentLock 下创建临时有序节点 Lock/002。
线程2查找 ParentLock 下所有临时有序节点并排序,发现 Lock/002 不是顺序最靠前;
于是,线程2向排在它前面的节点 Lock/001 注册 Watcher,用于监听 Lock/001 节点是否存在,同时抢锁失败进入等待。 - 线程3请求获得锁,继续创建 Lock/003 并判断排序,同样向 Lock/002 注册 Watcher,监听 Lock/002 是否存在,同时抢锁失败进入等待,以此类推。
- 当线程1任务结束显式调用命令删除 Lock/001,当然,若线程1在任务执行过程中崩溃了,一样会断开与zk的连接,Lock/001为临时节点,会自动删除。
- 因线程2一直监听着 Lock/001 的存在状态,所以当 Lock/001 被删除时,线程2会立刻收到通知。
此时,线程2会再次确认 Lock/002 的排序,若编号最小,则线程2获得锁。
数据库 - 乐观锁 & 悲观锁
select ... for update 若阻塞超时(innodb_lock_wait_timeout)会终止并报错。
https://blog.csdn.net/u013256816/article/details/92854794
常见面试题集锦
- Redis分布式锁操作的原子性,Redis内部是如何实现的?
insert into ... select语句把生产服务器炸了
原因:条件字段没有索引,导致全表扫描,逐行加锁。
https://mp.weixin.qq.com/s/3dticqm07HTvYC_HHqYq1Q- 如何解决库存超卖问题?
几个问题
版本号机制和MySQL的RR隔离级别有冲突吗?
MySQL的RR隔离级别:
读,一个事务里的select语句(普通select即为快照读)不会受到其他事务(不管其他事务有没有commit)的影响;
写,对一条记录而言,一个事务一旦update这条记录,其他事务只能等待这个事务commit才能update这条记录。
所以,虽然被并发的version字段通过select查不出来,但是在where条件语句中,这个字段会受到其他事务的影响,利用这点可以读到并发事务影响的数据,从而做出判断,防止覆盖。
https://dev.mysql.com/doc/refman/8.0/en/innodb-transaction-isolation-levels.html
注:update语句就是一个事务:mysql默认采用AutoCommit模式,也就是每个SQL都是一个事务,并不需要显式的执行事务;
若AutoCommit关闭,那么每个SQL都默认开启一个事务,但只有显式的执行commit,这个事务才会被提交。
for update 与 lock in share mode 的区别
- for update,IX(意向排他锁,又称写锁)
并发时A的 for update 会阻塞B的 for update(排他读锁)及写,直到B获取锁或中止报错(innodb_lock_wait_timeout超时)。 - lock in share mode,IS(意向共享锁,又称读锁)
并发时A的 lock in share mode 不会阻塞B的 lock in share mode(共享读锁),但会阻塞B的 for update 及写,直到所有IS锁被释放。
若A有CUD(此时是阻塞的),则B有CUD时会中止失败(避免死锁)。
备注:“写”表示CUD,即 INSERT / UPDATE / DELETE;B表示其他事务;快照读(即,不加锁的SELECT)不受影响,CUD默认加排他锁。
lock in share mode 与 select 有什么区别,如何选用?
上面我们知道,lock in share mode 不会阻塞其他事务的 lock in share mode,select(快照读)本身也不会,那为什么还需要 lock in share mode?
其实是看问题的切入点不同,其他事务用 lock in share mode,也是为了避免查询的数据被修改导致 幻读 / 脏读。
所以,如果 “其他事务” 中的查询没有这个顾虑,那完全可以用select,也能减少加锁的开销。
参考资料
漫画:什么是CAS机制?(进阶篇)
漫画:什么是分布式锁?
漫画:如何用Zookeeper实现分布式锁?
基于Redis的分布式锁和Redlock算法